Web Crawler Sederhana Dengan PHP Simple HTML DOM Parser
14 May 2019 | Tags: Crawler Sederhana Dengan PHP Simple HTML DOM Parser, PHP Simple HTML DOM Parser, Web Crawler Sederhana, Web Crawler Sederhana dengan CI PHP Simple HTML DOM, Web Crawler Sederhana dengan CodeIgniter
Pada artikel kali ini kita akan membahas cara mendapatkan atau memanipulasi elemen HTML data dari situs web eksternal dengan PHP Simple HTML DOM Parser.
Dengan library ini anda dapat menemukan elemen HTML berdasarkan id, class, tags dan sebagainya seperti halnya menggunakan jQuery.
Pada contoh ini kita akan mencoba studi kasus sederhana. Mengambil data dari web eksternal seperti gambar dibawah ini menggunakan CodeIgniter.
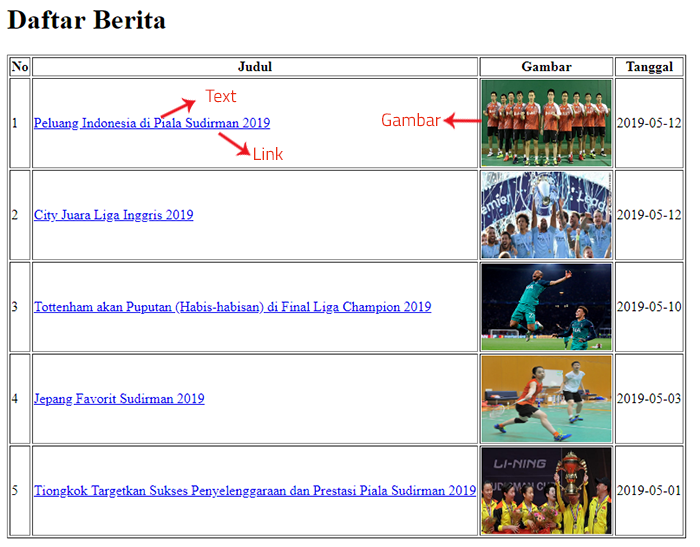
Pada contoh tampilan tabel tersebut kita akan mengambil kolom judul, gambar dan tanggal pada tiap baris tabel. Pada Kolom judul kita bisa urai lagi menjadi text dan link. Sementara dari kolom gambar kita akan mengambil path gambar-nya. Setelah kita berhasil melakukan crawling, hasilnya kita simpan ke MySql.
Persiapan Pembuatan Web Crawler
- CodeIgniter, pada latihan ini kita akan menggunakan CI 3.1.10
- Download PHP Simple HTML DOM Parser di https://sourceforge.net/projects/simplehtmldom/files/
- Cara-cara mengakses elemen HTML di https://simplehtmldom.sourceforge.io/
- File contoh (bisa di download nanti.)
Langkah-langkah Pembuatan Web Crawler dengan PHP Sederhana Dengan PHP Simple HTML DOM Parser
Buat Database dengan nama: dbcraw (nama lain boleh)
1. Buat tabel dengan nama tbl_craw
CREATE TABLE tbl_crawl ( id int(10) unsigned NOT NULL AUTO_INCREMENT, judul varchar(255) DEFAULT NULL, tanggal date DEFAULT NULL, url varchar(500) DEFAULT NULL, gambar varchar(255) DEFAULT NULL, PRIMARY KEY (id), UNIQUE KEY CK2 (url) )
2. Jadikan file PHP Simple HTML DOM Parser sebagai Helper
Setelah anda download file PHP Simple HTML DOM Parser, copy ke folder Framework CodeIgniter di:
application/helpers/simple_html_dom_helper.php (Ingat nama file ditambahkan _helper)
3. Buat Model Craw_model.php
Buat model dengan nama Craw_model: application/models/Craw_model.php.
Model ini untuk memroses data hasil crawling ke tbl_craw. Adapun model ini berisi script sebagai berikut:
<?php
class Craw_model extends CI_Model{
var $tables ="tbl_crawl";
var $pk ="id";
public function getAll()
{
return $this->db->get($this->tables)->result();
}
}
?>
4. Buat Controller Craw
Buat controller dengan nama controllers:
application/controllers/Craw.php. Controller ini melakukan proses crawling. Controller ini berisi method:
- index: berfungsi untuk menampilkan menu utama.
- tampil: berfungsi untuk menampilkan isi tbl_craw yang merupakan hasil crawling.
- get_contens: berfungsi untuk melakukan crawling mengambil data dari website tujuan. Dalam contoh ini kita menggunakan sumber localhost. Pada prinsipnya sama dengan mengambil data secara online.
<?php
defined('BASEPATH') OR exit('No direct script access allowed');
class Craw extends CI_Controller {
function __construct()
{
parent::__construct();
$this->load->helper('simple_html_dom');
$this->load->model('Craw_model');
}
public function index()
{
$data["pageTitle"] = "Crawler Sederhana Dengan PHP Simple HTML DOM Parser";
$this->load->view('pages/menu', $data);
}
public function tampil()
{
$data["pageTitle"] = "Daftar Hasil Crawler";
$data['record']=$this->Craw_model->getAll();
$this->load->view('pages/tampil', $data);
}
public function get_contens()
{
$data["pageTitle"] = "Hasil Crawler";
$data["pesan"]="";
$html = file_get_html('http://localhost/contoh/index.html');
foreach($html->find('table[class=contoh] tr') as $row)
{
if($row->find('td',1))
{
$judul = strip_tags($row->find('td',1)->innertext);
$url=$row->find('a',0)->href;
$tanggal=$row->find('td',3)->innertext;
$gambar=$row->find('img',0)->src;
$data1=array('judul'=>$judul,
'tanggal'=>$tanggal,
'url'=>$url,
'gambar'=>$gambar);
if($this->db->insert("tbl_crawl",$data1))
{
$data["pesan"].="Sukses input <br />";
}
else
{
$data["pesan"].="Gagal input <br />";
}
}
}
$this->load->view('pages/get_contents', $data);
}
}
5. Buat View
1. menu: application/views/pages/menu.php Untuk menampilkan menu
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title><?php echo $pageTitle;?></title>
<style>
body
{
font-family:Verdana, Geneva, sans-serif;
}
</style>
</head>
<body>
<h1><?php echo $pageTitle;?></h1>
<h3><a href="<?php echo base_url()?>craw/get_contens">CRAWLING</a> | <a href="<?php echo base_url()?>craw/tampil">LIHAT HASIL</a></h3>
</body>
</html>
2. tampil: application/views/pages/tampil.php
Untuk menampilkan record tbl_craw hasil crawling
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title><?php echo $pageTitle;?></title>
<style>
body
{
font-family:Verdana, Geneva, sans-serif;
}
</style>
</head>
<body>
<h1><?php echo $pageTitle;?></h1>
<table cellpadding="1" cellspacing="1" bgcolor="#999999">
<tr bgcolor="#CCCCCC">
<th>No</th>
<th>Judul</th>
<th>Tanggal</th>
<th>Url</th>
<th>Gambar</th>
</tr>
<?php
$i=1;
foreach($record as $r)
{
?>
<tr bgcolor="#FFFFFF">
<td><?php echo $i++;?></td>
<td><?php echo $r->judul;?></td>
<td><?php echo $r->tanggal;?></td>
<td><?php echo $r->url;?></td>
<td><?php echo $r->gambar;?></td>
</tr>
<?php
}
?>
</table><br />
<a href="<?php echo base_url()?>craw">MENU UTAMA</a>
</body>
</html>
3. get_contents: application/views/pages/get_contents.php
Untuk menampilkan pesan hasil crawling.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title><?php echo $pageTitle;?></title>
<style>
body
{
font-family:Verdana, Geneva, sans-serif;
}
</style>
</head>
<body>
<h1><?php echo $pageTitle;?></h1>
<?php
echo $pesan;
?>
<br />
<a href="<?php echo base_url()?>craw/">MENU UTAMA</a> | <a href="<?php echo base_url()?>craw/tampil">LIHAT HASIL</a>
</body>
</html>
6. Buat File Contoh untuk di-Crawl
File ini untuk contoh website yang nantinya akan dijadikan target untuk di Crawling. Pisahkan file ini dan simpan dalam folder khusus di lokasi file PHP anda, misalnya folder dinamakan contoh. Sehingga nanti file ini diakses dengan alamat url: http://localhost/contoh/index.html. Nah URL ini nantikan akan diakses oleh web crawler. Adapun script dari file contoh ini sebagai berikut:
<html xmlns="http://www.w3.org/1999/xhtml">
<head>
<meta http-equiv="Content-Type" content="text/html; charset=utf-8" />
<title>Contoh Dokumen</title>
</head>
<body>
<h1>Daftar Berita</h1>
<table class="contoh" border="1">
<tr>
<th>No</th>
<th>Judul</th>
<th>Gambar</th>
<th>Tanggal</th>
</tr>
<tr>
<td>1</td>
<td><a href="http://www.abc.com/1.html">Peluang Indonesia di Piala Sudirman 2019</a></td>
<td><img src="images/01.jpg" width="150" height="100" alt="01" /></td>
<td>2019-05-12</td>
</tr>
<tr>
<td>2</td>
<td><a href="http://www.abc.com/2.html">City Juara Liga Inggris 2019</a></td>
<td><img src="images/02.jpg" width="150" height="100" alt="02" /></td>
<td>2019-05-12</td>
</tr>
<tr>
<td>3</td>
<td><a href="http://www.abc.com/3.html">Tottenham akan Puputan (Habis-habisan) di Final Liga Champion 2019</a></td>
<td><img src="images/03.jpg" width="150" height="100" alt="03" /></td>
<td>2019-05-10</td>
</tr>
<tr>
<td>4</td>
<td><a href="http://www.abc.com/4.html">Jepang Favorit Sudirman 2019</a></td>
<td><img src="images/04.jpg" width="150" height="100" alt="04" /></td>
<td>2019-05-03</td>
</tr>
<tr>
<td>5</td>
<td><a href="http://www.abc.com/5.html">Tiongkok Targetkan Sukses Penyelenggaraan dan Prestasi Piala Sudirman 2019</a></td>
<td><img src="images/05.jpg" width="150" height="100" alt="05" /></td>
<td>2019-05-01</td>
</tr>
</table>
</body>
</html>
7. Menjalankan crawler
Seperti pembahasan di awal, aplikasi ini kita bedakan menjadi 2 yaitu:
- Aplikasi web crawler untuk melakukan crawling yang dibuat dengan CodeIgniter
- Website contoh, yang dijadikan tujuan untuk di-crawl.
Untuk menjalankan aplikasi, silahkan ketikkan: http://localhost/craw/craw.
Selamat Mencoba!
Download Web Crawler Sederhana
Klik tombol Facebook / Twitter / Google + untuk Download
Komentar tentang Web Crawler Sederhana Dengan PHP Simple HTML DOM Parser
Pagi Bang Komang, sy ingin menanyakan bagaimana cara mengaplikasikan web crawler untuk google scholar. Terimakasih.
Maaf, anda ingin melakukan proses apa dari Google Scholar
mengambil data citasi dan data judul yang ada di masing masing user bang komang.